大数据处理基本概念学习。
基本定义
SLA
SLA(Service-Level Agreement),也就是服务等级协议,指的是系统服务提供者(Provider)对客户(Customer)的一个服务承诺。这是衡量一个大型分布式系统是否“健康”的常见方法。一种服务承诺最常见的四个指标,可用性、准确性、系统容量和延迟。
- 可用性(Availabilty)可用性指的是系统服务能正常运行所占的时间百分比。
- 准确性(Accuracy)导致系统产生内部错误(Internal Error)的有效请求数,除以这期间的有效请求总数。通常通过性能测试和查看系统日志的方式来评估。
- 系统容量(Capacity)在数据处理中,系统容量通常指的是系统能够支持的预期负载量是多少,一般会以每秒的请求数为单位(QPS Queries Per Second)来表示。
- 延迟(Latency)延迟指的是系统在收到用户的请求到响应这个请求之间的时间间隔。
批处理和流处理
无边界数据是一种不断增长,可以说是无限的数据集,有边界数据是一种有限的数据集。事件时间指的是一个数据实际产生的时间点,而处理时间指的是处理数据的系统架构实际接收到这个数据的时间点。
绝大部分情况下,批处理的输入数据都是有边界数据,同样的,输出结果也一样是有边界数据。所以在批处理中,我们所关心的更多会是数据的事件时间。
批处理架构通常会被设计在以下这些应用场景中:
- 日志分析:日志系统是在一定时间段(日,周或年)内收集的,而日志的数据处理分析是在不同的时间内执行,以得出有关系统的一些关键性能指标。
- 计费应用程序:计费应用程序会计算出一段时间内一项服务的使用程度,并生成计费信息,例如银行在每个月末生成的信用卡还款单。
- 数据仓库:数据仓库的主要目标是根据收集好的数据事件时间,将数据信息合并为静态快照 (static snapshot),并将它们聚合为每周、每月、每季度的报告等。
流处理的输入数据基本上都是无边界数据。而流处理系统中是关心数据的事件时间还是处理时间,将视具体的应用场景而定。当流处理架构拥有在一定时间间隔(毫秒)内产生逻辑上正确的结果时,这种架构可以被定义为实时处理(Real-time Processing)。而如果一个系统架构可以接受以分钟为单位的数据处理时间延时,我们也可以把它定义为准实时处理(Near real-time Processing)。
流处理架构通常都会被设计在以下这些应用场景中:
- 实时监控:捕获和分析各种来源发布的数据,如传感器,新闻源,点击网页等。
- 实时商业智能:智能汽车,智能家居,智能病人护理等。
- 销售终端(POS)系统:像是股票价格的更新,允许用户实时完成付款的系统等。
Workflow设计模式
复制模式
复制模式通常是将单个数据处理模块中的数据,完整地复制到两个或更多的数据处理模块中,然后再由不同的数据处理模块进行处理。过滤模式
过滤模式的作用是过滤掉不符合特定条件的数据。分离模式
将数据分类为不同的类别来进行分组。合并模式
合并模式会将多个不同的数据集转换集中到一起,成为一个总数据集,然后将这个总的数据集放在一个工作流中进行处理。
发布订阅模式
如果你在处理数据的时候碰到以下场景,那么就可以考虑使用发布 / 订阅的数据处理模式。
系统的发送方需要向大量的接收方广播消息。系统中某一个组件需要与多个独立开发的组件或服务进行通信,而这些独立开发的组件或服务可以使用不同的编程语言和通信协议。
系统的发送方在向接收方发送消息之后无需接收方进行实时响应。
系统中对数据一致性的要求只需要支持数据的最终一致性(Eventual Consistency)模型。
分布式中的CAP定理
在任意的分布式系统中,一致性(Consistency),可用性(Availability)和分区容错性(Partition-tolerance)这三种属性最多只能同时存在两个属性。
C - 一致性:在线性一致性的保证下,所有分布式环境下的操作都像是在单机上完成的一样。
A - 可用性:在分布式系统中,任意非故障的服务器都必须对客户的请求产生响应。
P - 分区容错性:系统允许网络丢失从一个节点发送到另一个节点的任意多条消息。
常见的系统
CP 系统:Google BigTable, Hbase, MongoDB, Redis, MemCacheDB,这些存储架构都是放弃了高可用性(High Availablity)而选择 CP 属性的。
AP 系统:Amazon Dynamo 系统以及它的衍生存储系统 Apache Cassandra 和 Voldemort 都是属于 AP 系统
CA 系统:Apache Kafka 是一个比较典型的 CA 系统。
Lambda架构
Lambda 架构总共由三层系统组成:批处理层(Batch Layer),速度处理层(Speed Layer),以及用于响应查询的服务层(Serving Layer)
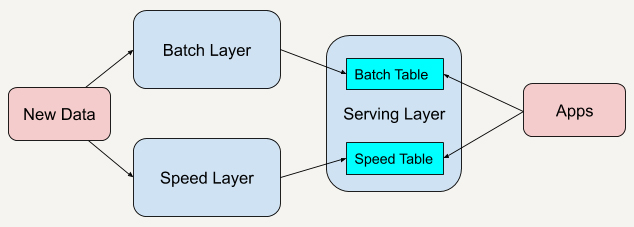
批处理层存储管理主数据集(不可变的数据集)和预先批处理计算好的视图。批处理层使用可处理大量数据的分布式处理系统预先计算结果。它通过处理所有的已有历史数据来实现数据的准确性。这意味着它是基于完整的数据集来重新计算的,能够修复任何错误,然后更新现有的数据视图。输出通常存储在只读数据库中,更新则完全取代现有的预先计算好的视图。速度处理层会实时处理新来的大数据。速度层通过提供最新数据的实时视图来最小化延迟。速度层所生成的数据视图可能不如批处理层最终生成的视图那样准确或完整,但它们几乎在收到数据后立即可用。而当同样的数据在批处理层处理完成后,在速度层的数据就可以被替代掉了。
一个查询,既通过批处理层兼顾了数据的完整性,也可以通过速度层弥补批处理层的高延时性,让整个查询具有实时性。
例子:
1.批处理部分。定时拉取业务库的数据,并在hive做批处理计算。
2.速度部分。通过订阅mysql数据库的binlog,实时获取数据库的增删改等的操作,通过kafka和flink,生成相关结果。
kappa架构
与 Lambda 架构不同的是,Kappa 架构去掉了批处理层这一体系结构,而只保留了速度层。你只需要在业务逻辑改变又或者是代码更改的时候进行数据的重新处理。
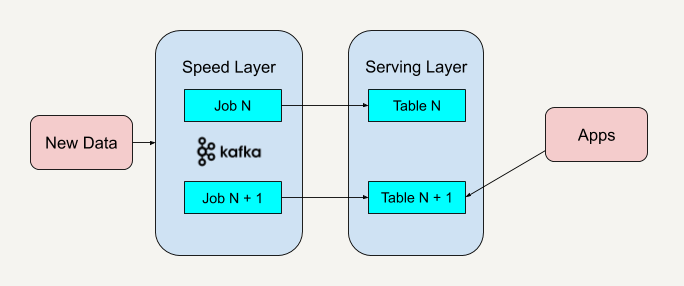
kappa架构使用更少的技术栈,实时和历史部分都是同一套技术栈。lambda架构为了解决历史部分和实时部分可能会使用不同的技术栈。
kappa架构使用了统一的处理逻辑。而lambda架构分别为历史和实时部分使用了两套逻辑。一旦需求变更,两套逻辑都要同时变更。
kappa架构具有流式处理的特点和优点。比如可以具有多个订阅者,比如具有更高的吞吐量。
MapReduce
MapReduce 通过简单的 Map 和 Reduce 的抽象提供了一个编程模型,可以在一个由上百台机器组成的集群上并发处理大量的数据集,而把计算细节隐藏起来。各种各样的复杂数据处理都可以分解为 Map 或 Reduce 的基本元素。复杂的数据处理可以分解为由多个 Job(包含一个 Mapper 和一个 Reducer)组成的有向无环图(DAG),然后每个 Mapper 和 Reducer 放到 Hadoop 集群上执行,就可以得出结果。
MR的缺点:
MapReduce 模型的抽象层次低,大量的底层逻辑都需要开发者手工完成。
只提供 Map 和 Reduce 两个操作。很多现实的数据处理场景并不适合用这个模型来描述。实现复杂的操作很有技巧性,也会让整个工程变得庞大以及难以维护。
在 Hadoop 中,每一个 Job 的计算结果都会存储在 HDFS 文件存储系统中,所以每一步计算都要进行硬盘的读取和写入,大大增加了系统的延迟。
只支持批数据处理,欠缺对流数据处理的支持。
MapReduce编程模型中,每一对map和reduce都会生成一个job,而且每一次都是写磁盘,这就造成启动时间变长,而且维护起来比较复杂;而Spark是链式计算,像map、flatmap、filter等transformation算子是不会触发计算的,只有在遇到像count、collect、saveAsTable等Action算子时,才会真正触发一次计算,对应会生成一个job。
Spark
Spark 最基本的数据抽象叫作弹性分布式数据集(Resilient Distributed Dataset, RDD),它代表一个可以被分区(partition)的只读数据集,它内部可以有很多分区,每个分区又有大量的数据记录(record)。
在任务(task)级别上,Spark 的并行机制是多线程模型,而 MapReduce 是多进程模型。
MapReduce每次的MR结果都是保存到磁盘,所以时间开销大;而Spark在执行应用程序是,中间的处理过程、数据(RDD)的缓存和shuffle操作等都是在内存允许的情况下,放在内存中的,所以耗时短。
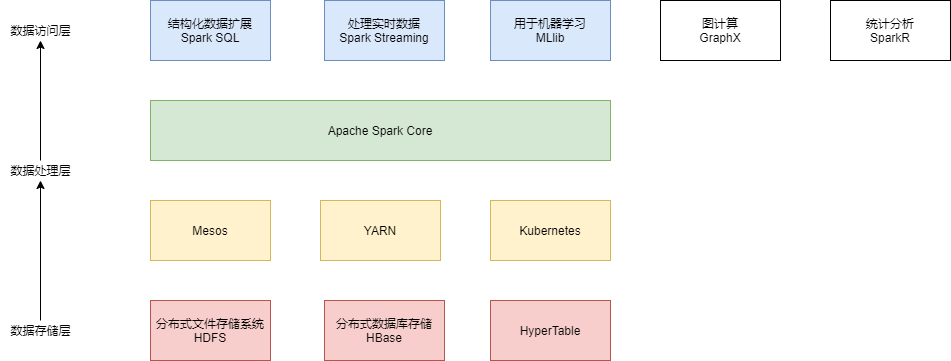
Hadoop中常见组件分层
RDD - 弹性分布式数据集
RDD 表示已被分区、不可变的,并能够被并行操作的数据集合。
分区:类似kafka的Topic,RDD由分区组成,本身只是一个逻辑概念,RDD 中的每个分区存有它在该 RDD 中的 index。通过 RDD 的 ID 和分区的 index 可以唯一确定对应数据块的编号,从而通过底层存储层的接口中提取到数据进行处理。在集群中,各个节点上的数据块会尽可能地存放在内存中,只有当内存没有空间时才会存入硬盘。这样可以最大化地减少硬盘读写的开销。
只读:只可以对现有的 RDD 进行转换(Transformation)操作生成新的RDD
并行:由于单个 RDD 的分区特性,使得它天然支持并行操作,即不同节点上的数据可以被分别处理,然后产生一个新的 RDD。
RDD的结构:
- Spark Context + Saprk Conf
SparkContext 是所有 Spark 功能的入口,它代表了与 Spark 节点的连接,可以用来创建 RDD 对象以及在节点中的广播变量等。一个线程只有一个 SparkContext。SparkConf 则是一些参数配置信息。
Partitions 和 partitioner:Partitions代表 RDD 中数据的逻辑结构,每个 Partition 会映射到某个节点内存或硬盘的一个数据块。目前有两种主流的分区方式:Hash partitioner 和 Range partitioner。Hash,顾名思义就是对数据的 Key 进行散列分区,Range 则是按照 Key 的排序进行均匀分区。此外我们还可以创建自定义的 Partitioner
依赖关系: Spark 支持两种依赖关系:窄依赖(Narrow Dependency)和宽依赖(Wide Dependency)。
窄依赖:父 RDD 的分区可以一一对应到子 RDD 的分区,一子多父,一子一父都是窄依赖
宽依赖:宽依赖就是父 RDD 的每个分区可以被多个子 RDD 的分区使用。即一父多子;
Spark 之所以要区分宽依赖和窄依赖是出于以下两点考虑:
窄依赖可以支持在同一个节点上链式执行多条命令,例如在执行了 map 后,紧接着执行 filter。相反,宽依赖需要所有的父分区都是可用的,可能还需要调用类似 MapReduce 之类的操作进行跨节点传递。
从失败恢复的角度考虑,窄依赖的失败恢复更容易,因为它只需要重新计算丢失的父分区即可,而宽依赖牵涉到 RDD 各级的多个父分区。
Checkpoint: 在计算过程中,对于一些计算过程比较耗时的 RDD,我们可以将它缓存至硬盘或 HDFS 中,标记这个 RDD 有被检查点处理过,并且
清空它的所有依赖关系。同时,给它新建一个依赖于 CheckpointRDD 的依赖关系,CheckpointRDD 可以用来从硬盘中读取 RDD 和生成新的分区信息。这样,当某个子 RDD 需要错误恢复时,回溯至该 RDD,发现它被检查点记录过,就可以直接去硬盘中读取这个 RDD,而无需再向前回溯计算。Storage Level 存储级别:一个枚举类型,用来记录 RDD 持久化时的存储级别,常用的有以下几个:
MEMORY_ONLY:只缓存在内存中,如果内存空间不够则不缓存多出来的部分。这是 RDD 存储级别的默认值。
MEMORY_AND_DISK:缓存在内存中,如果空间不够则缓存在硬盘中。
DISK_ONLY:只缓存在硬盘中。
MEMORY_ONLY_2 和 MEMORY_AND_DISK_2 等:与上面的级别功能相同,只不过每个分区在集群中两个节点上建立副本。
- 迭代函数(Iterator)和计算函数(Compute): 用来表示 RDD 怎样通过父 RDD 计算得到的。迭代函数会首先判断缓存中是否有想要计算的 RDD,如果有就直接读取,如果没有,就查找想要计算的 RDD 是否被检查点处理过。如果有,就直接读取,如果没有,就调用计算函数向上递归,查找父 RDD 进行计算。
RDD 的操作
RDD 的数据操作分为两种:转换(Transformation)和动作(Action)。
- 转换,转换操作都很懒,它只是生成新的 RDD,并且记录依赖关系。Spark 并不会立刻计算出新 RDD 中各个分区的数值。直到遇到一个动作时,数据才会被计算,并且输出结果给 Driver。这样设计的目的是,当动作比较简单时,可以很快的就返回。
Map/Filter/mapPartitions/groupByKey
- 动作
Collect/Reduce/Count/CountByKey
RDD 的持久化(缓存)
Spark 的 persist() 和 cache() 方法支持将 RDD 的数据缓存至内存或硬盘中,在缓存 RDD 的时候,它所有的依赖关系也会被一并存下来。所以持久化的 RDD 有自动的容错机制。如果 RDD 的任一分区丢失了,通过使用原先创建它的转换操作,它将会被自动重算。持久化可以选择不同的存储级,见上文。
总结
Spark 在每次转换操作的时候使用了新产生的 RDD 来记录计算逻辑,这样就把作用在 RDD 上的所有计算逻辑串起来形成了一个链条,但是并不会真的去计算结果。当对 RDD 进行动作 Action 时,Spark 会从计算链的最后一个 RDD 开始,利用迭代函数(Iterator)和计算函数(Compute),依次从上一个 RDD 获取数据并执行计算逻辑,最后输出结果。
Spark SQL
基于批处理模式对静态数据进行处理,Spark提供了类似于 SQL 的操作接口,允许数据仓库应用程序直接获取数据,允许使用者通过命令行操作来交互地查询数据,还提供两个 API:DataFrame API 和 DataSet API。
DataSet: DataSet 存储了每列的名称以及数据类型。DataSet 支持的转换和动作也和 RDD 类似,比如 map、filter、select、count、show 及把数据写入文件系统中。同样地,DataSet 上的转换操作也不会被立刻执行,只是先生成新的 DataSet,只有当遇到动作操作,才会把之前的转换操作一并执行,生成结果。
DataFrame: DataFrame 每一行的类型固定为 Row,他可以被当作 DataSet[Row]来处理,必须要通过解析才能获取各列的值。在Spark 2.0中DataFrame被统一为DataSet[Row]
简单来说,当每列数据类型程序都很确定时用DataSet, 列的类型不确定时,使用DataFrame,当使用非结构化的数据时,例如文本流数据,使用RDD比较合适。DataFrame 和 DataSet 的性能要比 RDD 更好,Spark SQL 中的Catalyst查询优化器会对语句进行分析,并生成优化过的 RDD 在底层执行。
Spark Streaming
Spark Streaming针对流数据的特性,根据时间片,将流数据拆分为无限的数据流,类似于微积分,然后对每一个数据片用批处理的方法进行处理。在内部,每个数据块就是一个 RDD,所以 Spark Streaming 有 RDD 的所有优点,处理速度快,数据容错性好,支持高度并行计算。但是,它的实时延迟相比起别的流处理框架比较高。在实际工作中,我们还是要具体情况具体分析,选择正确的处理框架。思考题
DStream: Spark Streaming 提供一个对于流数据的抽象 DStream,DStream 可以由来自 Apache Kafka、Flume 或者 HDFS 的流数据生成,也可以由别的 DStream 经过各种转换操作得来。
滑动窗口操作: StreamingContext 中最重要的参数是批处理的时间间隔,即把流数据细分成数据块的粒度。Window操作的两大特性是:
窗口长度和滑动间隔,它可以返回一个新的 DStream,这个 DStream 中每个 RDD 代表一段时间窗口内的数据。
Structured Streaming
一个建立在Spark SQL引擎之上可扩展且容错的流处理引擎。你可以使用与静态数据批处理计算相同的方式来表达流计算。当不断有流数据到达时,Spark SQL引擎将会增量地、连续地计算它们,然后更新最终的结果。
Structured Streaming 的三种输出模式。
- 完全模式(Complete Mode):整个更新过的输出表都被写入外部存储;
- 附加模式(Append Mode):上一次触发之后新增加的行才会被写入外部存储。如果老数据有改动则不适合这个模式;
- 更新模式(Update Mode):上一次触发之后被更新的行才会被写入外部存储。
Structured Streaming 并不会完全存储输入数据。每个时间间隔它都会读取最新的输入,进行处理,更新输出表,然后把这次的输入删除。Structured Streaming 只会存储更新输出表所需要的信息。在 Structured Streaming 发布以后,DataFrame既可以代表静态的有边界数据,也可以代表无边界数据。