Kafka相关的技术知识,本文内容均基于 Ubuntu 18.04 虚拟机进行。说明,本文档共涉及6台服务器
192.168.56.101 - kafka0
192.168.56.102 - kafka1
192.168.56.103 - kafka2
192.168.56.104 - zookeeper0
192.168.56.105 - zookeeper1
192.168.56.106 - zookeeper2
Kafka将所有消息组织成多个topic的形式存储,而每个topic又可以拆分为多个partition,每个partition又由一个一个的消息组成,每个消息都被标识了一个递增的序列号代表其进来的先后顺序,并按照顺序存储到partition;
producer选择一个topic,生产消息,消息会通过分配策略append到某个partition末尾
consumer选择一个topic, 通过id指定从那个位置开始消费消息。消费完成之后保留id,下次可以从这个位置开始继续消费,也可以从其他任意位置开始消费,这里的id即为offset。
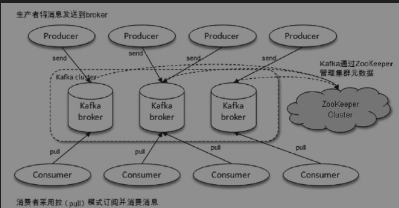
一个典型的 Kafka 体系架构包括若干 Producer、若干 Broker、若干 Consumer,以及一个ZooKeeper集群,其中ZooKeeper是Kafka用来负责集群元数据的管理、控制器的选举等操作的。Producer将消息发送到Broker,Broker负责将收到的消息存储到磁盘中,而Consumer负责从Broker订阅并消费消息。
Kafka的安装配置
Ubuntu服务器环境下Kafka安装与配置
Zookeeper安装与配置 - standalone模式
首先安装JAVA环境,下载jdk tar.gz安装包,上传到
/usr/local路径下,并执行tar -zxvf jdk-8u241-linux-x64.tar.gz解压。然后修改系统配置文件vim /etc/profile。1
2
3export JAVA_HOME=/usr/local/jdk1.8.0_241
export CLASSPATH=.:${JAVA_HOME}/jre/lib/rt.jar:${JAVA_HOME}/lib/dt.jar:${JAVA_HOME}/lib/tools.jar
export PATH=$PATH:${JAVA_HOME}/bin使得配置文件生效
source /etc/profile下载zookeeper, 这里, 解压到
/usr/local/,tar -zxvf /usr/local/apache-zookeeper-3.5.6-bin.tar.gz, 修改config目录下的zoo_sample.cfg重命名为zoo.cfg1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17zk中的时间单元,zk中所有时间都以此时间单元为基准,进行整数倍配置
tickTime=2000
follower在启动过程中,会从leader同步所有最新数据,确定自己能够对外服务的起始状态。
当follower在initLimit个tickTime还没完成数据同步时,则leader认为follower连接失败。
initLimit=10
leader与Follower之间通信请求和应答的时间长度。
当leader在syncLimit个tickTime还没有收到follower的应答,则认为leader已下线。
syncLimit=5
快照文件存储目录,如果不配置dataLogDir,则事务日志也会保存在这个目录(不推荐)
dataDir=/opt/data/zookeeper/data
事务日志存储目录
dataLogDir=/opt/data/zookeeper/logs
zk对外提供服务端口
clientPort=2181
the maximum number of client connections.
increase this if you need to handle more clients
[[maxClientCnxns]]=60修改zookeeper环境变量,节省操作步骤
vim /etc/profile1
2
3export ZOOKEEPER_HOME=/usr/local/apache-zookeeper-3.5.6
在文件的Path配置项里添加下列配置,注意有:号
:${ZOOKEEPER_HOME}/bin更新环境变量
source /etc/profile。启动ZookeeperzkServer.sh start。如果遇到Permission denied的问题就授权给zk的安装目录chmod -R 755 /usr/local/apache-zookeeper-3.5.6/。可以通过zkServer.sh status查看运行状态。通过jps可以看到zk对应的java进程。
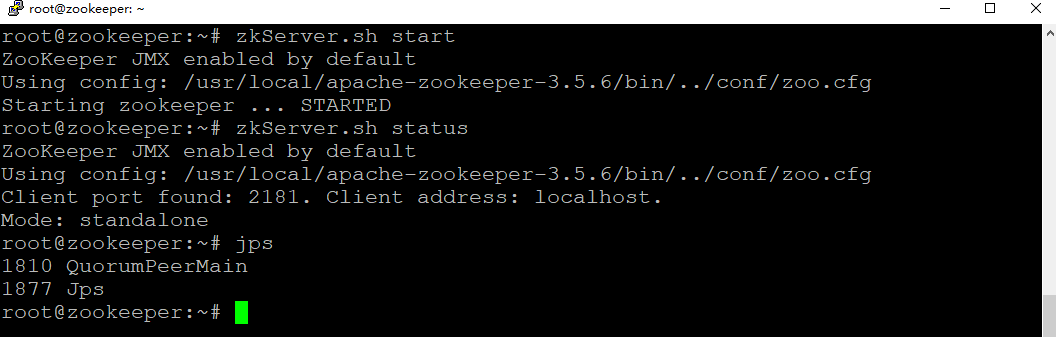
还可以通过以下命令通过zk客户端进行连接。
1 | 登录zk服务器 |
执行ls /
1 | [zk: 127.0.0.1:2181(CONNECTED) 0] ls / |
Zookeeper安装与配置 - 集群模式
与单机模式类似,集群模式需要对机器进行映射。我本地有三台zk的虚拟机,单机的配置,这三台集群都要有。
1 | 192.168.56.104 - zookeeper0 |
然后进入其中一台机器的ZooKeeper安装路径conf目录。这里我们选择先在IP为192.168.56.104的机器上进行配置,编辑conf/zoo.cfg文件,在该文件中添加以下配置:
server.N=N-server-IP:A:B 其中N是一个数字, 表示这是第几号server,它的值和myid文件中的值对应。N-server-IP是第N个server所在的IP地址。A是配置该server和集群中的leader交换消息所使用的端口。B配置选举leader时服务器相互通信所使用的端口。
1 | 在每个zk的配置文件里都同时配置三台机器 |
接着在${dataDir}路径下创建一个myid文件。myid里存放的值就是服务器的编号,即对应上述公式中的N,在这里第一台机器myid存放的值为1。ZooKeeper在启动时会读取myid文件中的值与zoo.cfg文件中的配置信息进行比较,以确定是哪台服务器。
1 | cd /opt/data/zookeeper/data |
同理在其它两个机器上分别修改zoo.cfg以及myid文件。
然后在三台机器上分别执行zkServer.sh start以及zkServer.sh status, 打印出如下日志:
1 | 192.168.56.104 - zookeeper0 |
可以看到,这3台机器中,一台机器作为Leader,其他两台服务器作为Follower。
Kafka安装与配置 - 单机模式
下载kafka, 这里, 解压到
/usr/local/,tar -zxvf /usr/local/kafka_2.13-2.4.0.tgz配置环境变量,
vim /etc/profile,按照下图配置后保存文件退出,执行source /etc/profile命令让刚才新增的Kafka环境变量设置生效。再在任一路径下输入kafka然后按Tab键,会提示补全Kafka运行相关脚本.sh文件,表示Kafka环境变量配置成功。
- 修改kafka配置,修改
$KAFKA_HOME/config目录下的server.properties文件,为了便于后续集群环境搭建的配置,需要保证同一个集群下broker.id要唯一,因此这里手动配置broker.id,直接保持与zk的myid值一致,同时配置日志存储路径。server.properties修改的配置如下:修改完后,保存文件然后启动Kafka,进入Kafka安装路径$KAFKA_HOME/bin目录下,执行启动KafkaServer命令。1
2
3
4
5
6# 指定的代理ID,由于是单机模式,这里指定zk节点id为1,及zookeeper0那台机器。
broker.id=1
# 指定Log存储路径
log.dirs=/opt/data/kafka-logs
# 指定kafka的安装路径,由于我zk没和kafka安装在同一台机器上所以这里要修改。
zookeeper.connect=192.168.56.104:2181执行jps命令查看Java进程,可以看到kafka的进程名,同时进入$KAFKA_HOME/logs目录下,查看server.log会看到KafkaServer启动日志,在启动日志中会记录KafkaServer启动时加载的配置信息。1
2-daemon参数表示使程序以守护进程的方式后台运行
kafka-server-start.sh -daemon /usr/local/kafka_2.13-2.4.0/config/server.properties
此时登录192.168.56.104这台zk可以再次查看目录结构:通过zk客户端登录1
zkCli.sh -server 192.168.56.104:2181
1
2
3
4
5
6在Kafka启动之前ZooKeeper中只有一个zookeeper目录节点,Kafka启动后目录节点如下:
[zk: 127.0.0.1:2181(CONNECTED) 0] ls /
[admin, brokers, cluster, config, consumers, controller, controller_epoch, isr_change_notification, latest_producer_id_block, log_dir_event_notification, zookeeper]
查看当前已启动的Kafka代理节点:输出信息显示当前只有一个Kafka代理节点,当前代理的brokerId为1
[zk: 127.0.0.1:2181(CONNECTED) 1] ls /brokers/ids
[1]
Kafka安装与配置 - 集群模式
集群与单机类似,这里只需修改server.properties文件中Kafka连接ZooKeeper的配置,将Kafka连接到ZooKeeper集群,配置格式为ZooKeeper服务器IP:ZooKeeper的客户端端口,多个ZooKeeper机器之间以逗号分隔开。
1 | zookeeper.connect=192.168.56.104:2181,192.168.56.105:2181,192.168.56.106:2181 |
执行下列命令复制kafka整个目录:
1 | cd /usr/local |
分别登录另外两台机器,修改server.properties文件中的broker.id依次为2和3, 并安装java环境,配置环境变量,同时也添加上述zk配置。
同样的,修改三台机器的advertised.listeners=PLAINTEXT://your.host.name:9092属性为具体的ip和端口。
listeners:kafka的连接协议名、主机名和端口,如果没有配置,将使用java.net.InetAddress.getCanonicalHostName()的返回值作为主机名
advertised.listeners:生产者和消费者使用的主机名和端口,如果没有配置,将使用listeners的配置,如果listeners也没有配置,将使用java.net.InetAddress.getCanonicalHostName()的返回值
然后在3台机器上启动kafka
1 | kafka-server-start.sh -daemon /usr/local/kafka_2.13-2.4.0/config/server.properties |
这个时候在任意一台zk服务器上执行ls /brokers/ids都会得到一下结果
1 | [zk: 127.0.0.1:2181(CONNECTED) 4] ls /brokers/ids |
Docker环境安装与配置
镜像下载
1 | docker pull wurstmeister/zookeeper |
zookeeper容器启动
1 | -d参数 表示后台运行容器,并返回容器ID |
kafka容器启动
单节点部署
1 | 启动Kafka(注意 修改IP为镜像安装IP) |
注意有以下四个参数:
- KAFKA_BROKER_ID=0
- KAFKA_ZOOKEEPER_CONNECT=
<zookeeper IP>:<zookeeper port> - KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://
:9092 - KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092
进入kafka容器内部
1 | docker exec -it kafka /bin/bash |
Kafka伪分布式环境部署
在同一台机器上启动多个Kafka Server 在单节点搭建的基础上再搭建一个节点,只需修改KAFKA_BROKER_ID以及端口
1 | docker run -d --name kafka1 \ |
然后再在/opt/kafka_2.12-2.4.0目录下执行
1 | ./bin/kafka-topics.sh --create --zookeeper 192.168.56.101:2181 --replication-factor 2 --partitions 2 --topic mytopic |
查看topic状态
1 | ./bin/kafka-topics.sh --describe --zookeeper 192.168.56.101:2181 --topic mytopic |
Isr表示存活的备份
Kafka Manager安装
下载kafka Manager这里,上传到/usr/local文件下,并解压tar -zxvf CMAK-2.0.0.2.tar.gz。Kafka Manager是用Scala语言开发的,通过sbt(Simple Build Tool)构建,sbt是对Scala或Java语言进行编译的一个工具,它类似于Maven, Gradle。需要通过以下方式进行源码编译
1 | cd ./CMAK-2.0.0.2 |
在下载了一晚上无果后,打开/root/.sbt看了看发现就下载了一个jar包,网上找了一份别人编译好的kafka-manager-2.0.0.2.zip。解压好上传,进行如下配置:
1 | cd /usr/local/kafka-manager-2.0.0.2/conf |
修改logback.xml文件中的${application.home}为..,即logs日志存储位置。启动kafka-manager
1 | 进入bin目录输入如下启动命令 |
关闭Kafka Manager。Kafka Manager没有提供关闭操作的执行脚本及命令,当希望关闭Kafka Manager时,可直接通过kill命令强制杀掉Kafka Manager进程。查看Kafka Manager进程,输入jps命令,其中ProdServerStart即为Kafka Manager进程。通过kill命令关闭Kafka Manager。同时,由于Kafka Manager运行时有一个类似锁的文件RUNNING_PID,位于Kafka Manager安装路径bin同目录下,为了不影响下次启动,在执行kill命令后同时删除RUNNING_PID文件,rm -f RUNNING_PID.
完成以上配置后打开http://192.168.56.101:9000/即可。
Kafka概念说明
基础概念
Kafka系统中有四种核心应用接口——生产者、消费者、数据流、连接器。
生产者
Kafka生产者可以理解成Kafka系统与外界进行数据交互的应用接口。生产者应用接口的作用是写入消息数据到Kafka中。Kafka系统提供了一系列的操作脚本,这些脚本放置在$KAFKA_HOME/bin目录中。其中,kafka-console-producer.sh脚本可用来作为生产者客户端。
生产者属性如下:
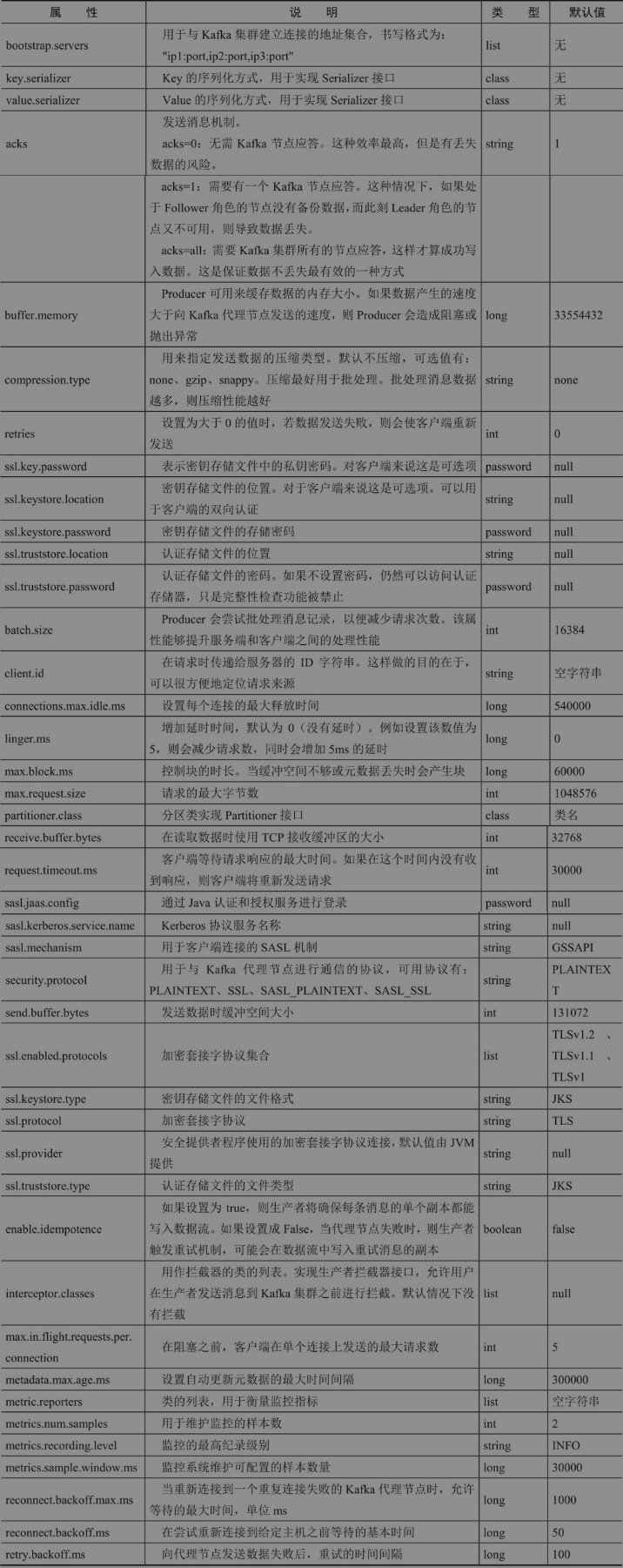
这里重点说明以下acks属性:
当acks=0时,生产者不用等待代理返回确认信息,而连续发送消息。显然这种方式加快了消息投递的速度,然而无法保证消息是否已被代理接受,有可能存在丢失数据的风险。
当acsk=1时,生产者需要等待Leader副本已成功将消息写入日志文件中。这种方式在一定程度上降低了数据丢失的可能性,但仍无法保证数据一定不会丢失。如果在Leader副本成功存储数据后,Follower副本还没有来得及进行同步,而此时Leader宕机了,那么此时虽然数据已进行了存储,由于原来的Leader已不可用而会从集群中下线,同时存活的代理又再也不会有从原来的Leader副本存储的数据,此时数据就会丢失。
当acks=-1时,Leader副本和所有ISR列表中的副本都完成数据存储时才会向生产者发送确认信息,这种策略保证只要Leader副本和Follower副本中至少有一个节点存活,数据就不会丢失。为了保证数据不丢失,需要保证同步的副本至少大于1,通过参数min.insync.replicas设置,当同步副本数不足此配置值时,生产者会抛出异常,但这种方式同时也影响了生产者发送消息的速度以及吞吐量。
消费者 与 消费者组
Kafka消费著可以理解成,外界从Kafka系统中获取消息数据的一种应用接口。消费者应用接口的主要作用是读取消息数据。Kafka系统提供了一系列的可操作脚本,这些脚本放置在$KAFKA_HOME/bin目录下。其中,有一个脚本可用来作为消费者客户端,即kafka-console-consumer.sh。
消费者属性如下:
消费者(Comsumer)以拉取(pull)方式拉取数据,它是消费的客户端。在Kafka中每一个消费者都属于一个特定消费组(ConsumerGroup),我们可以为每个消费者指定一个消费组,以groupId代表消费组名称,通过group.id配置设置。如果不指定消费组,则该消费者属于默认消费组test-consumer-group。同时,每个消费者也有一个全局唯一的id,通过配置项client.id指定,如果客户端没有指定消费者的id, Kafka会自动为该消费者生成一个全局唯一的id,格式为${groupId}-${hostName}-${timestamp}-${UUID前8位字符}。同一个主题的一条消息只能被同一个消费组下某一个消费者消费,但不同消费组的消费者可同时消费该消息。
消费者组的特点:
consumer group下可以有一个或多个consumer instance,consumer instance可以是一个进程,也可以是一个线程
group.id是一个字符串,唯一标识一个consumer group
consumer group下订阅的topic下的每个分区只能分配给某个group下的一个consumer(当然该分区还可以被分配给其他group)
消费者组的位移提交
Kafka消费的偏移量是存放在客户端的,由于ZK不适合做大批量的写操作,新版本Kafka增加了__consumeroffsets topic,将offset信息写入这个topic,摆脱对zookeeper的依赖(指保存offset这件事情)。__consumer_offsets中的消息保存了每个consumer group某一时刻提交的offset信息。
broker - 代理
对于kafka而言,broker可以简单地看作一个独立的Kafka服务节点或Kafka服务实例。大多数情况下也可以将Broker看作一台Kafka服务器,前提是这台服务器上只部署了一个Kafka实例。
topic - 主题 partition - 分区 以及 Replica - 副本
Kafka中的消息以主题(topic)为单位进行归类,生产者负责将消息发送到特定的主题(发送到Kafka集群中的每一条消息都要指定一个主题),而消费者负责订阅主题并进行消费。每一个代理都有唯一的标识id,这个id是一个非负整数。在一个Kafka集群中,每增加一个代理就需要为这个代理配置一个与该集群中其他代理不同的id, id值可以选择任意非负整数即可,只要保证它在整个Kafka集群中唯一,这个id就是代理的名字,也就是在启动代理时配置的broker.id对应的值。
主题是一个逻辑上的概念,它还可以细分为多个分区(partition),一个分区只属于单个主题。每个分区由一系列有序、不可变的消息组成,是一个有序队列。每个分区在物理上对应为一个文件夹,分区的命名规则为主题名称后接—连接符,之后再接分区编号,分区编号从0开始,编号最大值为分区的总数减1。每个分区又有一至多个副本(Replica),分区的副本分布在集群的不同代理上,以提高可用性。从存储角度上分析,分区的每个副本在逻辑上抽象为一个日志(Log)对象,即分区的副本与日志对象是一一对应的。每个主题对应的分区数可以在Kafka启动时所加载的配置文件中配置,也可以在创建主题时指定。当然,客户端还可以在主题创建后修改主题的分区数。由于Kafka副本的存在,就需要保证一个分区的多个副本之间数据的一致性,Kafka会选择该分区的一个副本作为Leader副本,而该分区其他副本即为Follower副本,只有Leader副本才负责处理客户端读/写请求,Follower副本从Leader副本同步数据。副本Follower与Leader的角色并不是固定不变的,如果Leader失效,通过相应的选举算法将从其他Follower副本中选出新的Leader副本。同一主题下的不同分区包含的消息是不同的,分区在存储层面可以看作一个可追加的日志(Log)文件,消息在被追加到分区日志文件的时候都会分配一个特定的偏移量(offset)。offset是消息在分区中的唯一标识,Kafka通过它来保证消息在分区内的顺序性,不过offset并不跨越分区,也就是说,Kafka保证的是分区有序而不是主题有序。
每一条消息被发送到broker之前,会根据分区规则选择存储到哪个具体的分区。如果分区规则设定得合理,所有的消息都可以均匀地分配到不同的分区中。如果一个主题只对应一个文件,那么这个文件所在的机器 I/O 将会成为这个主题的性能瓶颈,而分区解决了这个问题。在创建主题的时候可以通过指定的参数来设置分区的个数,当然也可以在主题创建完成之后去修改分区的数量,通过增加分区的数量可以实现水平扩展。
Kafka 为分区引入了多副本(Replica)机制,通过增加副本数量可以提升容灾能力。同一分区的不同副本中保存的是相同的消息(在同一时刻,副本之间并非完全一样),副本之间是“一主多从”的关系,其中leader副本负责处理读写请求,follower副本只负责与leader副本的消息同步。副本处于不同的broker中,当leader副本出现故障时,从follower副本中重新选举新的leader副本对外提供服务。Kafka通过多副本机制实现了故障的自动转移,当Kafka集群中某个broker失效时仍然能保证服务可用。
日志段
一个日志又被划分为多个日志段(LogSegment),日志段是Kafka日志对象分片的最小单位。与日志对象一样,日志段也是一个逻辑概念,一个日志段对应磁盘上一个具体日志文件和两个索引文件。日志文件是以“.log”为文件名后缀的数据文件,用于保存消息实际数据。两个索引文件分别以“.index”和“.timeindex”作为文件名后缀,分别表示消息偏移量索引文件和消息时间戳索引文件。
ISR
Kafka在ZooKeeper中动态维护了一个ISR(In-sync Replica),即保存同步的副本列表,该列表中保存的是与Leader副本保持消息同步的所有副本对应的代理节点id。分区中的所有副本统称为AR(Assigned Replicas)。所有与leader副本保持一定程度同步的副本(包括leader副本在内)组成ISR(In-Sync Replicas),ISR集合是AR集合中的一个子集。消息会先发送到leader副本,然后follower副本才能从leader副本中拉取消息进行同步,同步期间内follower副本相对于leader副本而言会有一定程度的滞后。如果一个Follower副本宕机或是落后太多,则该Follower副本节点将从ISR列表中移除。与leader副本同步滞后过多的副本(不包括leader副本)组成OSR(Out-of-Sync Replicas),由此可见,AR=ISR+OSR。在正常情况下,所有的 follower 副本都应该与 leader 副本保持一定程度的同步,即 AR=ISR,OSR集合为空。
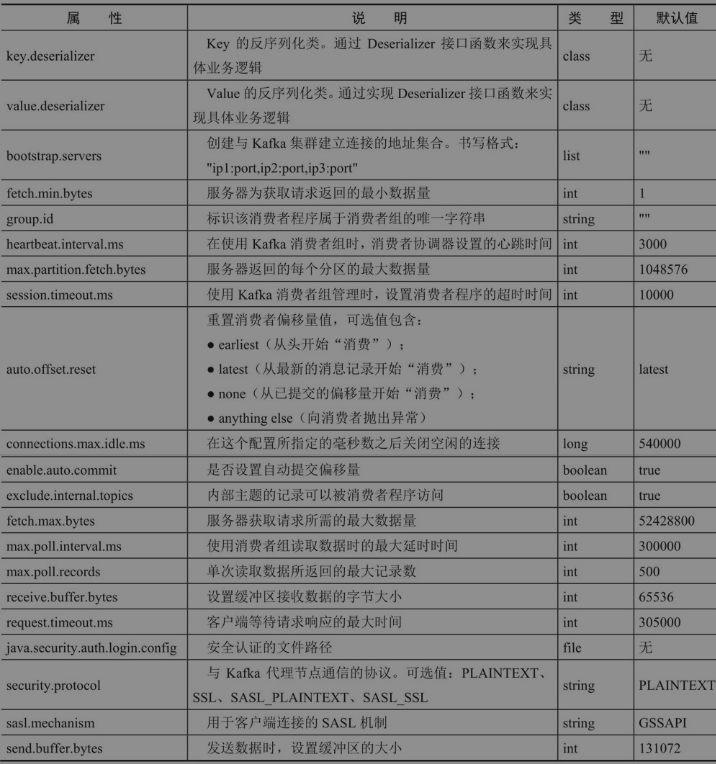
LEO是Log End Offset的缩写,它标识当前日志文件中下一条待写入消息的offset,offset为9的位置即为当前日志文件的LEO,LEO的大小相当于当前日志分区中最后一条消息的offset值加1。分区ISR集合中的每个副本都会维护自身的LEO,而ISR集合中最小的LEO即为分区的HW,对消费者而言只能消费HW之前的消息。
Kafka 的复制机制既不是完全的同步复制,也不是单纯的异步复制。事实上,同步复制要求所有能工作的 follower 副本都复制完,这条消息才会被确认为已成功提交,这种复制方式极大地影响了性能。而在异步复制方式下,follower副本异步地从leader副本中复制数据,数据只要被leader副本写入就被认为已经成功提交。在这种情况下,如果follower副本都还没有复制完而落后于leader副本,突然leader副本宕机,则会造成数据丢失。Kafka使用的这种ISR的方式则有效地权衡了数据可靠性和性能之间的关系。
Kafka的选举机制
每个代理启动时会创建一个KafkaController实例,当KafkaController启动后就会从所有代理中选择一个代理作为控制器,控制器是所有代理的Leader,因此这里也称之为Leader选举。除了在启动时会导致选举外,当控制器所在代理发生故障或ZooKeeper通过心跳机制感知控制器与自己的连接Session已过期时,也会再次从所有代理中选出一个节点作为集群的控制器。
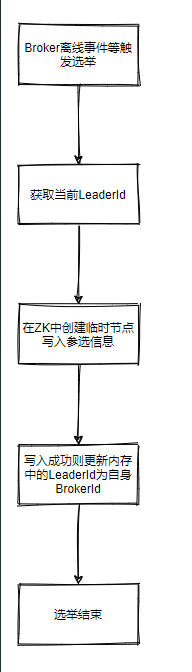
Kafka控制器选举的核心思想就是各代理通过争抢向Zookeeper的/controller节点请求写入自身的信息。
1 | // ZK中的/controller节点 |
controller_epoch: 用于记录控制器发生变更次数,即记录当前的控制器是第几代, 初始值为0,当控制器发生变更时,每选出一个新的控制器需将该字段加1, 如果请求的controller_epoch的值小于内存中controller_epoch的值,则认为这个请求是向已过期的控制器发送的请求,那么本次请求就是一个无效的请求。若该值大于内存中controller_epoch的值,则说明已有新的控制器当选了。通过该值来保证集群控制器的唯一性,进而保证相关操作一致性。该字段对应ZooKeeper的controller_epoch节点,通过登录ZooKeeper客户端执行get/controller_epoch命令,可以查看该字段对应的值。
leader_epoch:分区Leader更新次数。controller_epoch是相对代理而言的,而leader_epoch是相对于分区来说的。由于各请求达到顺序不同,控制器通过controller_epoch和leader_epoch来确定具体应该执行哪个命令操作。
Kafka的协调器
Kafka提供了三种协调器:
- 消费者协调器(ConsumerCoordinator):
每个消费者实例化时会实例化一个ConsumerCoordinator对象,消费者协调器负责同一个消费组下各消费者与服务端组协调器之间的通信;
消费者协调器负责处理更新消费者缓存的Metadata请求,负责向组协调器发起加入消费组的请求,负责对本消费者加入消费组前、后相应的处理,负责请求离开消费组(如当消费者取消订阅时),还负责向组协调器发送提交消费偏移量的请求。并通过一个心跳检测定时任务来检测组协调器的运行状况,或是让组协调器感知自己的运行状况。同时,Leader消费者的消费者协调器还负责执行分区的分配,当消费者协调器向组协调器请求加入消费组后,组协调器会为同一个组下的消费者选出一个Leader,成为Leader的消费者其ConsumerCoordinator收到的信息与其他消费者有所不同。Leader消费者的ConsumerCoordinator负责消费者与分区的分配,会在请求SyncGroupRequest时将分配结果发送给GroupCoordinator,而非Leader消费者(这里我们将其简称为Follower消费者), Follower消费者向GroupCoordinator发送SyncGroupRequest请求时分区分配结果参数为空,GroupCoordinator会将Leader副本发送过来的分区分配结果再返回给Follower消费者的ConsumerCoodinator。
- 组协调器(GroupCoordinator: 用于管理部分消费组和该消费组下每个消费者的消费偏移量;
组协调器(GroupCoordinator)负责对其管理的组员提交的相关请求进行处理,这里的组员即消费者。它负责管理与消费者之间建立连接,并从与之连接的消费者之中选出一个消费者作为Leader消费者,Leader消费者负责消费者分区的分配,在SyncGroupRequest请求时发送给组协调器,组协调器会在请求处理后返回响应时下发给其管理的所有消费者。同时,组协调器还管理与之连接的消费者的消费偏移量的提交,将每个消费者消费偏移量保存到Kafka的内部主题当中,并通过心跳检测来检测消费者与自己的连接状态。
消费者组确定协调器
确定consumer group位移信息写入__consumers_offsets的哪个分区,该分区leader所在的broker就是被选定的coordinator
1 | groupMetadataTopicPartitionCount由offsets.topic.num.partitions指定,默认是50个分区。 |
- 任务管理协调器(WorkCoordinator)
消费者组的再平衡 - rebalance
新成员入消费者组,消费者组成员崩溃或者主动离开消费者组,这三种都会触发kafka 消费者组的rebalance;
1 Join, 顾名思义就是加入组。这一步中,所有成员都向coordinator发送JoinGroup请求,请求入组。一旦所有成员都发送了JoinGroup请求,coordinator会从中选择一个consumer担任leader的角色,并把组成员信息以及订阅信息发给leader——注意leader和coordinator不是一个概念。leader负责消费分配方案的制定。
2 Sync,这一步leader开始分配消费方案,即哪个consumer负责消费哪些topic的哪些partition。一旦完成分配,leader会将这个方案封装进SyncGroup请求中发给coordinator,非leader也会发SyncGroup请求,只是内容为空。coordinator接收到分配方案之后会把方案塞进SyncGroup的response中发给各个consumer。这样组内的所有成员就都知道自己应该消费哪些分区了。
Kafka的基础操作
KafkaServer管理
单节点启动
1 | 进入bin目录 |
bin目录下的kafka-server-start.sh即为启动脚本。启动后会在$KAFKA_HOME/logs目录下创建相应的日志文件。

启动完毕后,登录ZooKeeper客户端查看相应节点信息。
1 | 启动zk客户端 |
JMX监控开启,需要将JMX_PORT配置添加到KafkaServer启动脚本kafka-server-start.sh文件中,该项监控可以在kafka-manager中看到。
1 | 在启动脚本中首行添加 |
也可以在启动命令中配置
1 | JMX_PORT=9999 kafka-server-start.sh -daemon ../config/server.properties |
集群启动
可以编写个脚本来启动集群中所有节点 # $?是指上一次命令执行的成功或者失败的状态。如果成功就是0,失败为1
1 | kafka-cluster-start.sh |
单节点关闭
执行bin目录下的kafka-server-stop.sh即可停止kafka。
1 | SIGNAL=${SIGNAL:-TERM} |
停止的原理是kill kafka的PID,由于我的kafka-manager和kafka0节点装在一起,所以会连代停止我的kafka-manager。
如果想准确的停止kafka,获取PID时可以使用PIDS=$(jps | grep -i 'Kafka' | awk '{print $1}')
集群关闭
与集群启动类似,编写一个调用bin目录下的kafka-server-stop.sh的脚本即可停止。
1 | kafka-cluster-stop.sh |
主题管理
主题创建
客户端通过执行kafka-topics.sh脚本创建一个主题。若开启了自动创建主题配置项auto.create.topics.enable=true,当生产者向一个还不存在的主题发送消息时,Kafka会自动创建该主题。
1 | 直接输入该脚本的名字可以查看有哪些命令参数 |
zookeeper参数是必传参数,用于配置Kafka集群与ZooKeeper连接地址,这里并不要求传递${ zookeeper.connect }配置的所有连接地址。为了容错,建议多个ZooKeeper节点的集群至少传递两个ZooKeeper连接配置,多个配置之间以逗号隔开。
partitions参数用于设置主题分区数,该配置为必传参数。Kafka通过分区分配策略,将一个主题的消息分散到多个分区并分别保存到不同的代理上,以此来提高消息处理的吞吐量。Kafka的生产者和消费者可以采用多线程并行对主题消息进行处理,而每个线程处理的是一个分区的数据,因此分区实际上是Kafka并行处理的基本单位。分区数越多一定程度上会提升消息处理的吞吐量,然而Kafka消息是以追加的形式存储在文件中的,这就意味着分区越多需要打开更多的文件句柄,这样也会带来一定的开销。
replication-factor参数用来设置主题副本数,该配置也是必传参数。副本会被分布在不同的节点上,副本数不能超过节点数,否则创建主题会失败
进入在server.properties中配置的log.dirs=/opt/data/kafka-logs对应的目录下,创建主题后会在${log.dir}目录下创建相应的分区文件目录,副本分别分布在不同的节点上。
1 | 以kafka0节点为例子,查看分区文件 |
主题删除
执行kafka-topics.sh脚本进行删除,若希望通过该脚本彻底删除主题,则需要保证在启动Kafka时所加载的server.properties文件中配置delete.topic.enable=true,该配置默认为false。否则执行该脚本并未真正删除主题,而是在ZooKeeper的/admin/delete_topics目录下创建一个与待删除主题同名的节点,将该主题标记为删除状态。主题在${log.dir}目录下对应的分区文件及在ZooKeeper中的相应节点并未被删除,这个时候需要你手动删除。
1 | kafka-topics.sh --delete --zookeeper 192.168.56.104:2181,192.168.56.105:2181,192.168.56.106:2181 --topic kafka-action |
直接执行的话,用zk客户端去看
1 | [zk: 192.168.56.104:2181(CONNECTED) 8] ls /admin/delete_topics |
查看主题
- 查看该集群下所有主题
1
kafka-topics.sh --list --zookeeper 192.168.56.104:2181,192.168.56.105:2181,192.168.56.106:2181
- 查看特定主题的信息
1
kafka-topics.sh --topic kafka-action --describe --zookeeper 192.168.56.104:2181,192.168.56.105:2181,192.168.56.106:2181
查看消息
Kafka生产的消息以二进制的形式存在文件中,Kafka提供了一个查看日志文件的工具类kafka.tools.DumpLogSegments。通过kafka-run-class.sh脚本,可以直接在终端运行该工具类
1 | 查看kafka-action-test主题下的消息内容 |
生产者
启动生产者
1 | broker-list 指定Kafka的代理地址列表 topic 指定消息被发送的目标主题 key.separator 指定key 和 消息之间的分隔符 |
生产者性能测试
1 | kafka-producer-perf-test.sh --num-records 10000 --record-size 1000 --topic kafka-action-test --throughput 10000 --producer-props bootstrap.servers=192.168.56.101:9092,192.168.56.102:9092,192.168.56.103:9092 |
kafka-producer-perf-test.sh脚本调用的是org.apache.kafka.tools.ProducerPerformance类
- topic 指定了生产者发送消息的目标主题
- num-records 测试时发送消息的总条数
- record-size 每条消息的字节数
- throughput 限流控制 throughput值小于0时则不进行限流;若该参数值大于0时,当已发送的消息总字节数与当前已执行的时间取整大于该字段时生产者线程会被阻塞一段时间。生产者线程被阻塞时,在控制台可以看到输出一行吞吐量统计信息;若该参数值等于0时,则生产者在发送一次消息之后检测满足阻塞条件时将会一直被阻塞。
上述命令执行结果如下:
1 | 10000 records sent, 4618.937644 records/sec (4.40 MB/sec), 895.99 ms avg latency, 1232.00 ms max latency, 940 ms 50th, 1199 ms 95th, 1220 ms 99th, 1232 ms 99.9th. |
- recores send 测试时发送的消息总数
- records/sec 每秒发送的消息数 - 吞吐量
- avg latency 消息处理的平均耗时 ms
- max latency 消息处理的最大耗时 ms
- X th %Xd的消息处理耗时
消费者
Kafka采用了消费组的模式,每个消费者都属于某一个消费组,在创建消费者时,若不指定消费者的groupId,则该消费者属于默认消费组。消费组是一个全局的概念,因此在设置group.id时,要确保该值在Kafka集群中唯一。同一个消费组下的各消费者在消费消息时是互斥的,也就是说,对于一条消息而言,就同一个消费组下的消费者来讲,只能被同组下的某一个消费者消费,但不同消费组的消费者能消费同一条消息。
启动消费者
kafka-console-consumer.sh脚本调用的是Kafka core工程下kafka.tools包下的ConsoleConsumer对象,该对象调用(org.apache.kafka.clients.consumer.KafkaConsumer)消费消息。
1 | kafka-console-consumer.sh --bootstrap-server 192.168.56.101:9092,192.168.56.102:9092,192.168.56.103:9092 --consumer-property group.id=consumer-test --topic kafka-action-test --from-beginning |
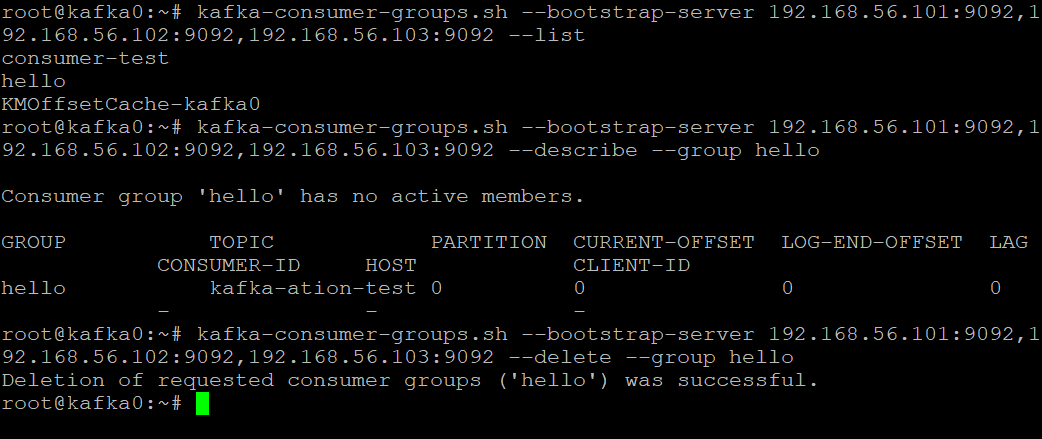
查看消费者组的信息
1 | 查看所有消费者组 |
消费者性能测试工具
1 | kafka-consumer-perf-test.sh --broker-list 192.168.56.101:9092,192.168.56.102:9092,192.168.56.103:9092 --threads 5 --messages 10000 --socket-buffer-size 10000 --num-fetch-threads 2 --group consumer-perf-test --topic kafka-action-test |
输出如下:
1 | start.time, end.time, data.consumed.in.MB, MB.sec, data.consumed.in.nMsg, nMsg.sec, rebalance.time.ms, fetch.time.ms, fetch.MB.sec, fetch.nMsg.sec |
Kafka的源码编译
环境搭建
安装Scala
Windows环境下,下载并安装Scala。先进入Scala官方网站这里下载相应的安装包并安装。
1 | 查询Scala版本 |
安装Gradle
进入Gradle官方网站这里下载Gradle安装包。将下载好的gradle-6.1.1-bin解压后,配置GRADLE_HOME以及%GRADLE_HOME%\bin到环境变量。
1 | 查询gradle版本 |
Kafka源码编译
先进入这里下载Kafka src 源码文件。进入源码根目录,执行gradle idea。